IMDB 데이터셋을 활용한 이진분류
이미지 자료나 코드 모두 한경훈 교수님의 자료에서 참조하였으며, 한경훈 교수님의 블로그 링크를 첨부합니다.
블로그 링크 : https://sites.google.com/site/kyunghoonhan/keras?authuser=0
IMDB 데이터셋
IMDB 데이터셋은 영화 리뷰에 대한 데이터로 리뷰가 긍정적인지 부정적인지에 대한 예측을 할 수 있습니다.
케라스의 tf.keras.datasets.imdb로부터 IMDB 데이터셋을 불러올 수 있습니다.
from tensorflow import keras
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(f"훈련용 : {len(train_data)}")
print(f"테스트용 : {len(test_data)}")
훈련용 : 25000
테스트용 : 25000
리뷰에 등장한 모든 단어를 처리할 수 없기때문에 (정보대비 계산비용이 큼)
등장빈도가 낮다면 unknown으로 전처리될 수 있습니다.
num_words = 10000이라면 등장빈도가 10,000등 안에 들지 않는 단어들은 unknown으로 전처리됩니다.
첫번째 훈련 데이터를 출력해보겠습니다.
정수열이 출력됩니다.
라벨을 출력해보니 긍정리뷰라는 것을 알 수 있습니다.
print(train_data[0][:10])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65]
print(train_labels[0])
1
각 정수는 등장빈도 순위를 나타내며
[가장 많이 등장한 단어, 14번 째로 많이 등장한 단어, ..]로 구성되어 있는 리뷰입니다.
그 단어가 뭔지 알기 위해선 사전이 필요합니다.
word_index = imdb.get_word_index()
print(word_index['the'])
print(word_index['and'])
print(word_index['a'])
1
2
3
word_index는 영어 단어를 정수로 바꾸어주는 사전입니다.
첫 번째 데이터를 확인하기 위해서는 정수를 영어단어로 바꾸어주는 사전이 필요합니다.
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
print(reverse_word_index[1])
print(reverse_word_index[2])
print(reverse_word_index[3])
the
and
a
이제 reverse_word_index를 활용하여 첫 번째 데이터를 디코딩 할 수 있지만 여기서 주의할 점이 있습니다.
정수로 이루어진 데이터에서 (훈련데이터와 테스트 데이터 모두) 0,1,2,3은 특별 토큰을 나타냅니다.
- 0 :
<PAD>(문장의 길이가 같아지도록 끼워넣는 더미, 여기서는 사용안함) - 1 :
<START>(문장의 시작을 알림) - 2 :
<UNK>(등장빈도가 낮은 어휘) - 3 :
<UNUSED>
따라서 제가 첫번째 훈련데이터에 대하여
[가장 많이 등장한 단어, 14번 째로 많이 등장한 단어, ..]로 구성되어 있다고 한 설명은 사실 틀렸습니다.
1은 문장의 시작을 알리는 토큰이며 14는 11번 째로 많이 등장한 단어입니다.
decoded_review = " ".join([reverse_word_index.get(i - 3, "?") for i in train_data[0]])
decoded_review[:39]
'? this film was just brilliant casting '
첫 번째 훈련데이터는 캐스팅에 대해 긍정적인 리뷰였네요.
멀티 핫 인코딩
리뷰 데이터를 신경망으로 학습시키기 위해서는 입력 크기가 같아야합니다.
하지만 리뷰들은 각각 다른 길이의 정수열로 인코딩되어 있습니다.
print(len(train_data[0]))
print(len(train_data[1]))
print(len(train_data[2]))
218
189
141
모두 10,000의 길이를 가지는 멀티 핫 벡터로 다시 인코딩하겠습니다. 그러면 신경망의 입력 뉴런수가 10,000으로 결정될 수 있습니다. 규칙은 다음과 같습니다.
- 벡터의 길이는 어휘의 개수
- 한번이라도 등장하는 인덱스의 자리에는 1 (여러번 중복되도 여전히 1)
- 등장하지 않는 인덱스의 자리에는 0
import numpy as np
def vectorize_sequences(sequences, dimension=10000): # sequences : 리뷰 데이터
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
y_train = train_labels
y_test = test_labels
x_train[0][:10]
array([0., 1., 1., 0., 1., 1., 1., 1., 1., 1.])
vectorize_sequences 함수의 dimension는 벡터의 차원을 결정합니다.
저희는 처음 데이터를 불러올 때 등장빈도가 10,000등 안에 드는 단어들만을 불러왔습니다. 따라서 등장빈도를 다르게 불러온다면 dimension의 값을 다르게 줄 수 있습니다.
이진분류
입력 뉴런 수를 통일하였으니 이제 신경망을 구성할 수 있습니다.
이진 분류는 마지막 뉴런 수를 2로 잡고 소프트맥스를 사용하기보다는 마지막 뉴런 수를 1로 잡고 시그모이드 함수를 사용합니다.
시그모이드 함수의 출력값은 0~1 사이 값이기 때문에 출력값으로 0.6이 나왔다면, 긍정 확률이 0.6 부정확률이 0.4라고 할 수 있습니다.
from keras import models
from keras.layers import Dense
from tensorflow.keras.utils import plot_model
model = models.Sequential()
model.add(Dense(16, input_shape=(10000,), activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
plot_model(model, show_shapes=True, show_layer_activations=True)
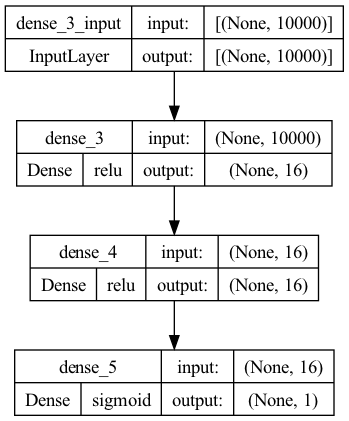
학습설정을 합니다.
이전에 손실함수를 설정할 때에는 정수 라벨이라면 sparse_categorical_crossentropy를, 원핫인코딩이 되어있다면 categorial_crossentropy를 사용한다고 했습니다.
이진분류를 할때는 손실함수를 binary_crossentropy로 설정합니다.
- 다중분류, 정수라벨 :
sparse_categorical_crossentropy - 다중분류, 원핫인코딩 :
categorial_crossentropy - 이진분류 :
binary_crossentropy
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics="accuracy")
데이터는 통상적으로 훈련 데이터 (train data), 검증 데이터(validation data), 테스트 데이터(test data) 셋으로 나눕니다.
검증 데이터는 최적의 하이퍼 파라미터 값을 찾기 위해 사용됩니다.
하이퍼 파라미터란 학습률, 학습회수, 파라미터 수 등 컴퓨터가 스스로 학습할 수 없고 사람이 직접 지정해주어야 하는 값입니다.
최적의 하이퍼 파라미터 값을 찾는 과정을 튜닝이라고 하는데 테스트 데이터를 튜닝하는데 사용하게 되면 신경망이 테스트 데이터에 맞춰지기 때문에 신뢰할 수 없는 정확도가 나오게 됩니다.
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=15,
batch_size=512,
validation_data=(x_val, y_val),
verbose=False)
2023-06-09 13:17:53.944718: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
2023-06-09 13:17:55.109637: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
fit 메소드로 리턴된 history 객체에는 각 epoch별 훈련 데이터의 손실함수, 정확도 값 그리고 검증 데이터의 손실함수, 정확도 값이 사전형태로 저장되어 있습니다.
다음은 각 epoch별 훈련 데이터의 손실함수 값과 검증 데이터의 손실함수 값을 나타낸 그래프 입니다.
import matplotlib.pyplot as plt
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
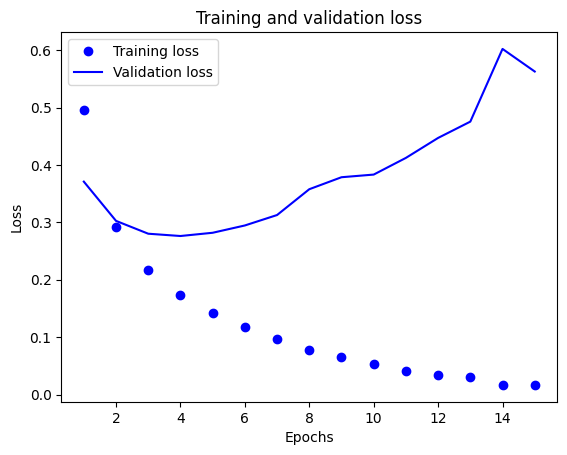
훈련 데이터의 손실함수값은 0으로 수렴하는데 반해 검증 데이터의 값은 3 epoch 이후로 증가하는 것을 확인할 수 있습니다.
신경망의 가중치들이 훈련 데이터에 지나치게 맞춰지게 되니, 즉 과적합이 발생하여 이런 현상이 나타납니다.
과적합을 막기 위해서는 여러가지 방법이 있으나 이번엔 그저 epoch를 낮춰서 과적합이 일어나기 전까지만 학습해보겠습니다.
model = keras.Sequential([
Dense(16, input_shape=(10000,), activation="relu"),
Dense(16, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics="accuracy")
model.fit(x_train, y_train, epochs=4, batch_size=512,verbose=False)
results = model.evaluate(x_test, y_test)
print("\n")
print(results)
2023-06-09 13:24:15.761915: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
22/782 [..............................] - ETA: 3s - loss: 0.2957 - accuracy: 0.8920
2023-06-09 13:24:19.225945: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
782/782 [==============================] - 4s 5ms/step - loss: 0.3083 - accuracy: 0.8786
[0.30827558040618896, 0.878600001335144]
손실함수값은 0.3 정도, 정확도는 0.87 정도로 나왔네요.
predict메소드로 테스트 데이터의 예측 확률을 확인해볼까요?
print(model.predict(x_test)[0])
782/782 [==============================] - 3s 3ms/step
[0.22998719]
print(y_test[0])
0
예측 확률이 0.5보다 낮은 걸보니 모델은 부정 리뷰라고 예측했고 라벨을 확인해보니 맞춘걸 알 수 있습니다.
decoded_review = " ".join([reverse_word_index.get(i - 3, "?") for i in test_data[0]])
print(decoded_review)
? please give this one a miss br br ? ? and the rest of the cast rendered terrible performances the show is flat flat flat br br i don't know how michael madison could have allowed this one on his plate he almost seemed to know this wasn't going to work out and his performance was quite ? so all you madison fans give this a miss
디코딩해서 살펴보니 악평이 맞네요
이 모델을 활용하여 어떤 단어를 입력받았을 때 단어에 대해 긍정 리뷰에서의 등장빈도와 부정 리뷰에서의 등장 빈도를 출력하는 함수를 만들 수 있습니다.
예를 들면, ‘good’이라는 단어를 입력 받으면 ‘good’이라는 단어가 긍정 리뷰에 등장한 빈도와 부정 리뷰에 등장한 빈도가 출력됩니다. 당연히 긍정 리뷰에 등장한 빈도가 더 많겠죠?
predictions = model.predict(x_test)
782/782 [==============================] - 3s 4ms/step
def frequency(word):
print(f"어휘 : {word}")
positive = []
for idx in range(len(predictions)):
if predictions[idx]>0.5:
positive.append(idx)
negative = []
for idx in range(len(predictions)):
if predictions[idx]<0.5:
negative.append(idx)
test_positive = test_data[positive]
count=0
for seq in test_positive:
count+=np.sum(np.array(seq)==(word_index[word]+3))
print(f"긍정 리뷰에서 등장 빈도 : {count}")
test_negative = test_data[negative]
count=0
for seq in test_negative:
count+=np.sum(np.array(seq)==(word_index[word]+3))
print(f"부정 리뷰에서 등장 빈도 : {count}")
for word in ["good","bad","best"]:
frequency(word)
print("="*50)
어휘 : good
긍정 리뷰에서 등장 빈도 : 7908
부정 리뷰에서 등장 빈도 : 6646
==================================================
어휘 : bad
긍정 리뷰에서 등장 빈도 : 2135
부정 리뷰에서 등장 빈도 : 6988
==================================================
어휘 : best
긍정 리뷰에서 등장 빈도 : 4445
부정 리뷰에서 등장 빈도 : 1735
==================================================
IMDB 데이터를 이용해 이진 분류를 해보았습니다.
다음 포스팅에서는 로이터 뉴스 데이터셋을 활용하여 다중분류를 해보도록 하겠습니다.